BBRv2 总结
BBRv1的问题
- 带宽探测过于激进,导致丢包率过高。
BBRv1的ProbeBW阶段为了探测带宽,会周期性地使用
1.25的增益系数发送数据。在网络缓冲队列很小(Shallow Buffer)的情况下,这额外25%的流量无法被吸收,会直接导致周期性的丢包。 - 抢占性过强,对其他流不公平。
BBRv1主要根据自己测量的
BtlBw来发送数据,不太会因为网络拥堵而主动大幅降低速率。当BBRv1与传统的基于丢包的算法(如CUBIC、Reno)共享一个瓶颈链路时,会发生以下情况:- BBRv1为了探测带宽,会持续填满(甚至溢出)队列。
- CUBIC等算法检测到丢包或高延迟后,会立刻大幅降低自己的发送速率(进入拥塞避免阶段)。
- BBRv1看到CUBIC让出了带宽,会认为网络瓶颈变大了,于是进一步增加自己的发送速率,抢占更多的带宽。
- 难以感知真正的拥塞。
BBRv1通过
deliveryRate来估计带宽。但在某些复杂场景下,例如发生乱序(reordering)或聚合确认(ACK aggregation)时,ACK返回的模式会欺骗BBRv1,使其在短时间内误以为交付速率非常高,从而高估了BtlBw。这会导致它以过高的速率发送数据,加剧网络拥塞。 - ProbeRTT阶段导致带宽利用率下降。
为了测量真实
RTprop,BBRv1会进入ProbeRTT状态,将飞行数据量降至极低的4个数据包。这个过程持续至少200毫秒。在带宽延迟积(BDP)非常大的高速长距离网络中,4个数据包远不足以填满管道。这意味着每隔10秒,网络带宽就会有200毫秒的时间被闲置,在高带宽场景下这会造成可观的吞吐量损失。
BBRv1通过在收到每个ACK时测量交付速率来更新瓶颈带宽(BtlBw):DeliveryRate = 交付的字节数 / 交付这些字节所花费的时间
聚合确认导致虚假交付率
- 发送方以100Mbps的速率,发送了P1, …, P100 一共100个数据包。
- ACK被聚合: 接收方为了效率,将这100个包的ACK攒了起来,然后在一个非常短的时间窗口内(比如几毫秒内)连续发回给发送方。
- 发送方在T1时刻收到ACK-1,几微秒(μs)后在T2时刻收到ACK-2,又过了几微秒在T3时刻收到ACK-3…
- 当收到ACK-2时,BBRv1计算交付速率。
- 交付的字节数 = 1个包的大小(例如1500字节)。
- 交付时间 ≈ T2 - T1(几微秒)。
- DeliveryRate = 1500 bytes / (几 μs)
- 这个计算结果会可能会得出高达几十Gbps甚至更高的瞬时交付速率。
- 这个巨大且错误的DeliveryRate样本进入了BBRv1的BtlBw滑动窗口最大值滤波器。由于它是窗口内的最大值,BtlBw会被立刻更新为这个虚假的高值。
- 在接下来的6-10个RTT周期内,它会用这个被污染的BtlBw来计算pacing_rate,从而以远超实际网络承受能力的速率疯狂发送数据,瞬间填满所有路由器缓冲区,造成严重的延迟飙升和大量丢包。
乱序导致虚假交付率
- 发送方依次发送了P1(序列号0-999), P2(1000-1999), P3(2000-2999)。
- 乱序到达: 接收方先收到了P1,然后是P3,P2因为网络路径问题被延迟了。
- 收到P1后,接收方回复ACK 1000。收到P3后,由于P2还没到,无法进行累积确认。它只能再次回复ACK 1000(这是一个重复ACK)。
- 过了一会儿,被延迟的P2到达。此时,接收方它立刻发送了一个新的累积确认ACK 3000。
- 发送方先是正常地收到了ACK 1000。紧接着,它可能很快就收到了ACK 3000。
- 当ACK 3000到达时,BBRv1发现,新确认的数据量是3000 - 1000 = 2000字节(P2和P3的数据)。
- 计算出DeliveryRate = 2000 bytes / (一个很短的ACK到达间隔)
BBRv2的改进
更快的启动阶段
BBRv2对启动阶段做了优化,使其在初始带宽探测时能更快地收敛,同时减少了在启动末期造成的排队溢出。
拥塞感知的带宽探测
BBRv2的带宽探测不再是“盲目”地以1.25倍增益向前冲,而是变得小心翼翼。
- 引入拥塞容忍度:BBRv2设定一个丢包率或ECN标记率的上限。在ProbeBW探测带宽时,如果发现丢包/ECN标记超个阈值,会立即停止增加发送速率,甚至会降低速率。
- 更长的探测周期:BBRv2不再执着于在单个RTT内完成带宽探测,而是将探测过程拉长到多个RTT,以更温和的方式增加流量,观察网络是否能承受。
更精细的队列管理
BBRv2致力于将瓶颈路由器的排队量维持在一个很小的目标值(通常是1个BDP以内)。
- ProbeBW的演进:它不仅探测带宽上限,还探测队列的承受能力。它会估算因为自己探测行为而增加的额外排队量。如果排队量增长过快,即使没丢包,它也会放缓探测步伐。这使得BBRv2在探测时产生的队列更小、更可控。
- ProbeRTT的改进:BBRv2认识到
ProbeRTT的带宽浪费问题。新的ProbeRTT不再强制将飞行数据降到4个包,而是降低到一个略低于当前估计BDP的水平。这样做既能有效地排空在途队列以测量RTprop,又不会让网络管道完全干涸,从而显著提高了在高BDP网络中的平均吞吐量。
拥塞时的主动退让与公平性
这是BBRv2最关键的改进,解决了与CUBIC等算法的共存问题。
- 感知持续拥塞:BBRv2会跟踪数据包在网络中的“留存时间”(in-flight time)。如果发现数据包的RTT持续高于
RTprop,说明网络中存在持续的排队。 - 主动降低
BtlBw估计:当BBRv2确认存在持续拥塞时,它不再固执地坚守自己测量的BtlBw。相反,它会主动地、按比例地调低自己的BtlBw估计值。 - 信息共享:在多条BBRv2流共享一个瓶颈时,它们能够通过感知共同的排队情况,更快地收敛到一个公平的带宽分配点。
BBRv2核心思想
BBRv2在基于建模的基础上,引入拥塞信号作为强约束,主动控制排队。
- 模型与信号结合: BBRv2不再像v1一样几乎完全无视丢包。它将丢包率和ECN标记视为明确的拥塞信号,并用这些信号来判断其带宽模型是否过于激进,从而进行实时约束。
- 主动控制在途队列 (Inflight Queue): 将网络中的排队延迟维持在一个非常低的水平。它通过引入
inflight_hi和inflight_lo两个“水位线”来精确控制在途数据量,以主动管理和消除不必要的排队。 - 可证明的公平性: 当BBRv2与CUBIC等基于丢包的算法共享瓶颈时,如果它检测到持续的拥塞(高丢包率或持续排队),它会主动降低自己的带宽估计值 (
BtlBw),为其他流量“让路”。 - 对无线网络更友好: 通过对拥塞信号的感知,BBRv2能更好地处理无线网络中的随机丢包,避免像v1那样因过于激进的探测而导致性能恶化。
BBRv2实现
状态机
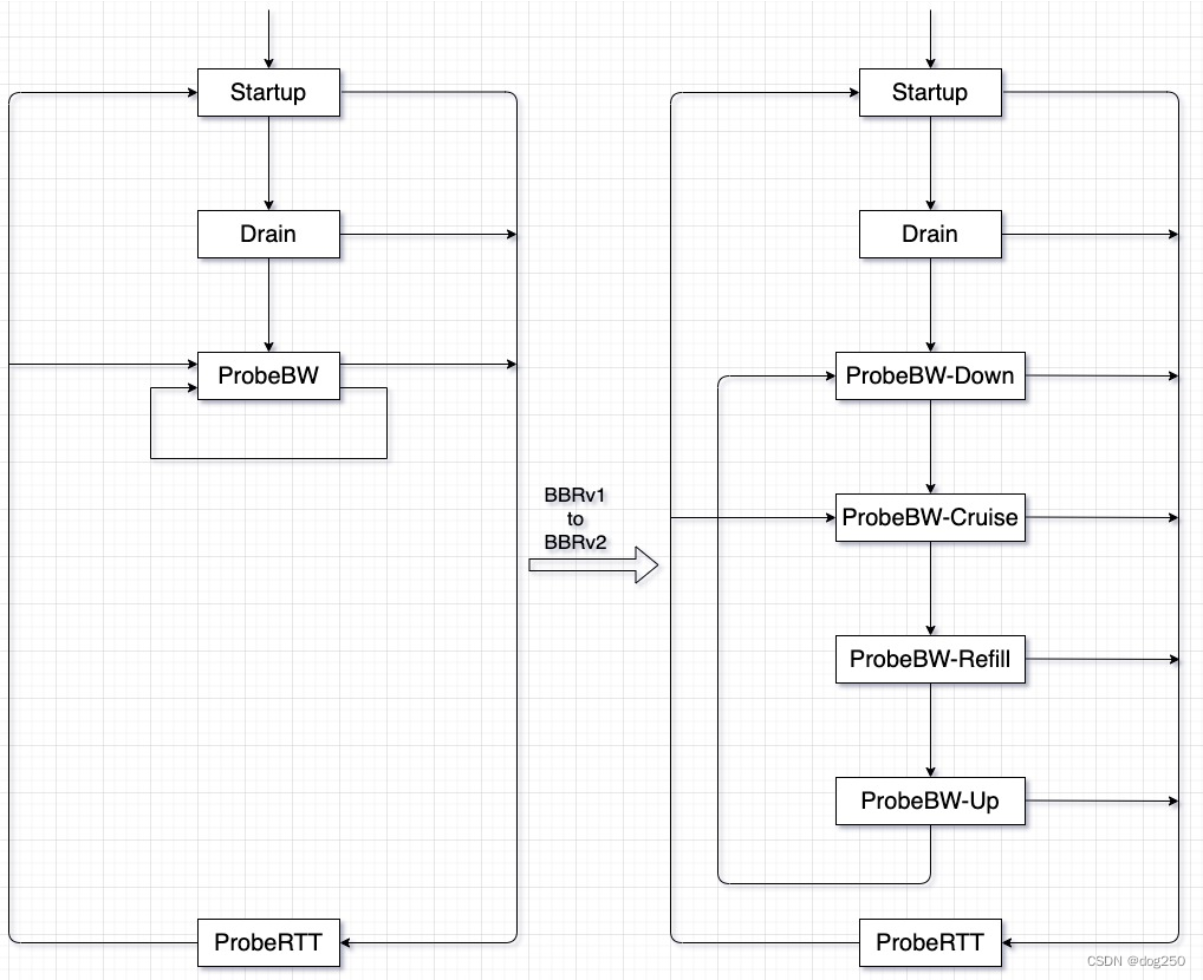
BBRv2 核心变量
bw:MaxBwFilter输出的带宽估计值(基于 delivery_rate 样本)。min_rtt:MinRTTFilter 输出的最小 RTT。bdp = bw * min_rtt:带宽时延积(目标 in-flight 数据量)。pacing_rate:发送速率上限。cwnd:拥塞窗口上限。inflight_hi/inflight_lo:可接受的 in-flight 数据上下界。bw_hi/bw_lo:带宽估计的上下界。extra_acked:用于补偿 ACK 聚合。offload_budget:TSO/GSO/LRO 相关的额外预算。
STARTUP 阶段
目标:快速填满管道并探测最大带宽。
-
进入条件:连接建立或应用恢复发送。
-
pacing_gain:
BBRStartupPacingGain = 4 * ln(2) ≈ 2.77 -
cwnd_gain:
BBRStartupCwndGain = 2.0 -
pacing_rate:
pacing_rate = pacing_gain * bw -
cwnd:
inflight = cwnd_gain * bdp + extra_acked cwnd = min(cwnd, inflight) -
退出条件:
- 探测到带宽已“填满管道”(bw 无显著增长)
- 丢包率超过阈值(BBRLossThresh ≈ 2%),触发提前退出。
-
更新变量:
- 如果丢包:
inflight_hi = max(inflight * BBRBeta, inflight - lost)(BBRBeta ≈ 0.7) - 否则:继续指数增加 pacing_rate,直到退出。
- 如果丢包:
DRAIN 阶段
目标:把 Startup 期间积累的队列 drain 掉,使 in-flight ≈ BDP。
-
进入条件:Startup 退出时。
-
pacing_gain:
pacing_gain = 1 / BBRStartupPacingGain ≈ 0.36 -
cwnd_gain:
BBRStartupCwndGain = 2.0 -
pacing_rate:
pacing_rate = pacing_gain * bw -
cwnd:
inflight = cwnd_gain * bdp + extra_acked cwnd = min(cwnd, inflight) -
退出条件: 当 in-flight ≤ BDP(即估计队列清空),进入 ProbeBW。
-
更新变量:
-
在退出 Drain 时,初始化:
inflight_hi = inflight /* 记录此时安全的上界 */ bw_hi = bw
-
PROBE_BW 阶段
目标:稳态运行,维持高利用率和低延迟,同时持续探测可用带宽。
分为 四个子状态:
(a) UP
-
目标:试探更高带宽。
-
pacing_gain = 1.25
-
cwnd_gain = 2.0
-
pacing_rate:
pacing_rate = 1.25 * bw -
丢包检测:
if (lost > inflight * BBRLossThresh): inflight_hi = max(inflight * BBRBeta, inflight - lost) enter DOWN -
退出条件:
- 没有丢包 → 经过 1 RTT 进入 DOWN。
- 有丢包 → 立即进入 DOWN。
(b) DOWN
-
目标:轻度 drain,避免长期积压。
-
pacing_gain = 0.9
-
cwnd_gain = 2.0
-
pacing_rate:
pacing_rate = 0.9 * bw -
退出条件:
- 队列减少,inflight ≈ BDP → 进入 CRUISE。
(c) CRUISE
-
目标:稳定发送,维持公平性。
-
pacing_gain = 1.0
-
cwnd_gain = 2.0
-
pacing_rate:
pacing_rate = bw -
退出条件:
- 定时器触发(约 8–16 个 RTT)→ 重新进入 REFILL,开始下一个 probe cycle。
- 如果 min_rtt 过期(>10s),进入 ProbeRTT。
(d) REFILL
- 目标:把 inflight 补回 BDP。
- pacing_gain = 1.0
- cwnd_gain = 2.0
- 退出条件: 当 inflight ≈ BDP,进入 UP。
PROBE_RTT 阶段
目标:排空队列以测量真实 min_rtt。
-
进入条件:
min_rtt超过MinRTTFilterLen(≈10s)未更新。 -
pacing_gain = 1.0
-
cwnd_gain = 0.5
-
cwnd:
inflight = 0.5 * bdp + extra_acked cwnd = max(inflight, BBRMinPipeCwnd) /* 至少4个MSS */ -
持续时间:
- 至少 200ms,且 ≥1 RTT。
-
退出条件:
- 测得新的 min_rtt,或超时结束。
- 返回 ProbeBW。
丢包与 ECN 响应(全局逻辑)
-
丢包判据:
if lost > inflight * BBRLossThresh (≈ 2%): inflight_hi = max(inflight * BBRBeta, inflight - lost) if state == ProbeBW_UP: enter ProbeBW_DOWN -
ECN 判据:与丢包类似,如果 ECN-CE 标记比例超过阈值,同样下调 inflight_hi/bw_hi。
-
长期约束:
- pacing_rate 和 cwnd 永远不会超过
bw_hi和inflight_hi。 - 也不会低于
bw_lo和inflight_lo。
- pacing_rate 和 cwnd 永远不会超过