TCP协议:拥塞控制
产生原因
网络中数据传输需要超过了网络能够处理的最大容量:
- 数据管道容量
- 网络设备缓冲区
产生控制拥塞后,数据包累积导致延迟,超过缓冲限制则大量丢失,影响传输效率和吞吐。
算法分类
| 拥塞控制大类 | 具体算法 | 特点 |
|---|---|---|
| 基于丢包 | TCP Tahoe | 慢启动、拥塞避免、 |
| TCP Reno | 在Tahoe的基础上引入快速重传和快速恢复 | |
| TCP NewReno | ||
| TCP BIC | 通过二分搜索算法快速找到cwnd | |
| TCP CUBIC | BIC的优化版本,使用三次函数平滑增长cwnd | |
| 基于延迟 | TCP Vegas | |
| Fast TCP | ||
| LEDBAT | ||
| Copa | ||
| 基于丢包+延迟 | TCP Nice | |
| WebRTC GCC | ||
| 基于建模 | TCP Westwood | |
| BBR/BBRv2 | ||
| 基于学习 | PCC | |
| Gemini |
算法评价指标
- 吞吐量:在单位时间内成功传输的数据量。
- 带宽利用率:吞吐量与网络最大可能吞吐量(即带宽)的比值
- 时延:数据从发送端到接收端所需的时间。
- 抖动:数据包在网络中传输时延的变化量。
- 丢包率:在传输过程中丢失的数据包占总发送数据包的比例。
- 收敛速度:网络条件发生变化时,调整其发送速率以达到稳定状态所需的时间。
- 公平性:当多个连接共享同一网络链路时,算法如何分配带宽。
基于丢包
TCP Tahoe
Tahoe算法主要包含三个核心机制:
- 慢启动。
- 初始的cwnd为1个MSS。
- 每当发送方收到一个ACK,cwnd就会增加一个MSS。因此每经过一个RTT,cwnd会翻倍(指数增长)
- 慢启动会一直持续,直到cwnd达到一个预设的慢启动阈值ssthresh。
- 拥塞避免。
- 当cwnd超过ssthresh后,从慢启动切换到拥塞避免阶段。
- 每经过一个RTT,cwnd就会增加一个MSS。
- 拥塞避免阶段会一直持续,直到发生丢包。
- 快速重传:当发送方连续收到三个重复的ACK时,会认为发生丢包。发送方立即重传丢失的报文段,不必等待超时。并且当发生丢包或者重传超时,则:
- 将ssthresh设置为当前cwnd的一半。
- 将cwnd重置为1个MSS。重新进入慢启动阶段。
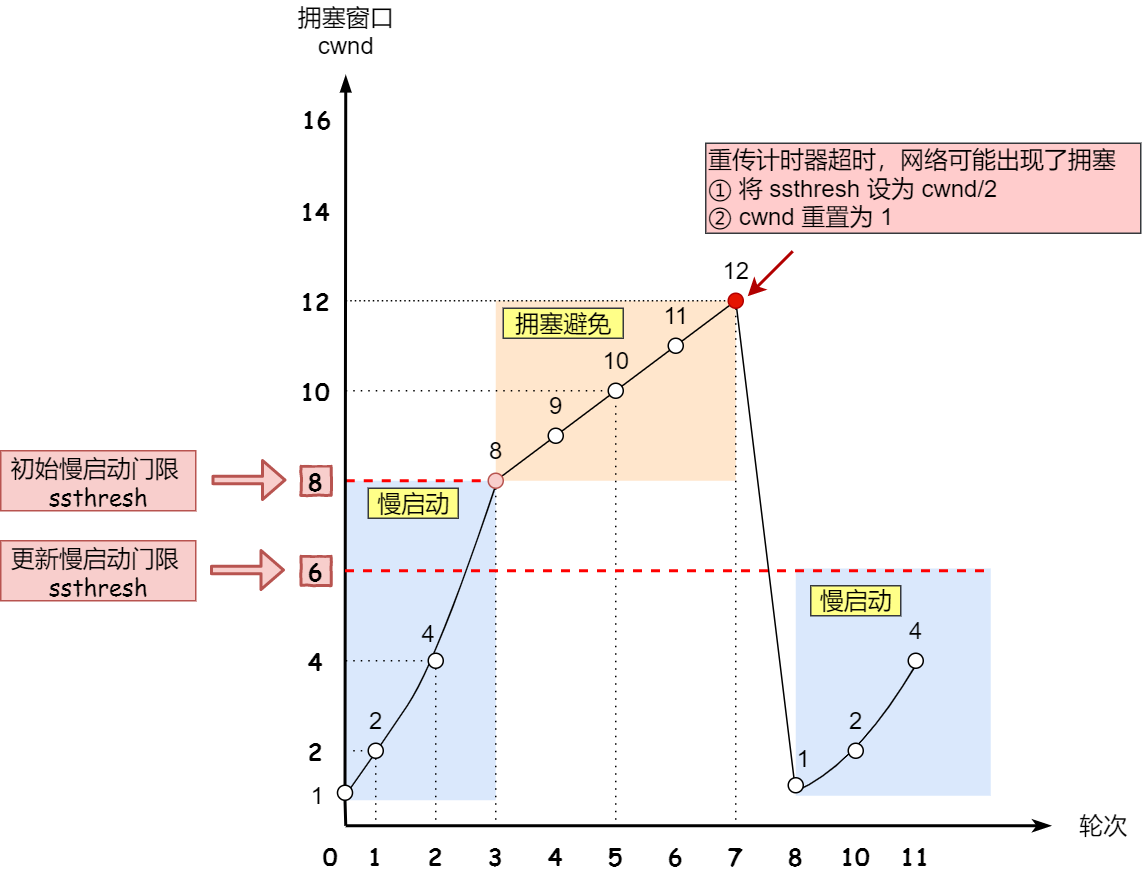
算法缺陷:
- 在发生丢包时,将cwnd重置为1,会导致连接吞吐量大幅下降。尤其是在高带宽、高延迟的网络环境中会严重影响性能。
- 将所有丢包事件都视为严重的网络拥塞,实际并非如此。
TCP Reno
Reno算法相比Tahoe多了一个快速恢复:
- 慢启动。
- 拥塞避免。
- 快速重传:快速重传:当发送方连续收到三个重复的ACK时,会认为发生丢包。发送方立即重传丢失的报文段,不必等待超时。
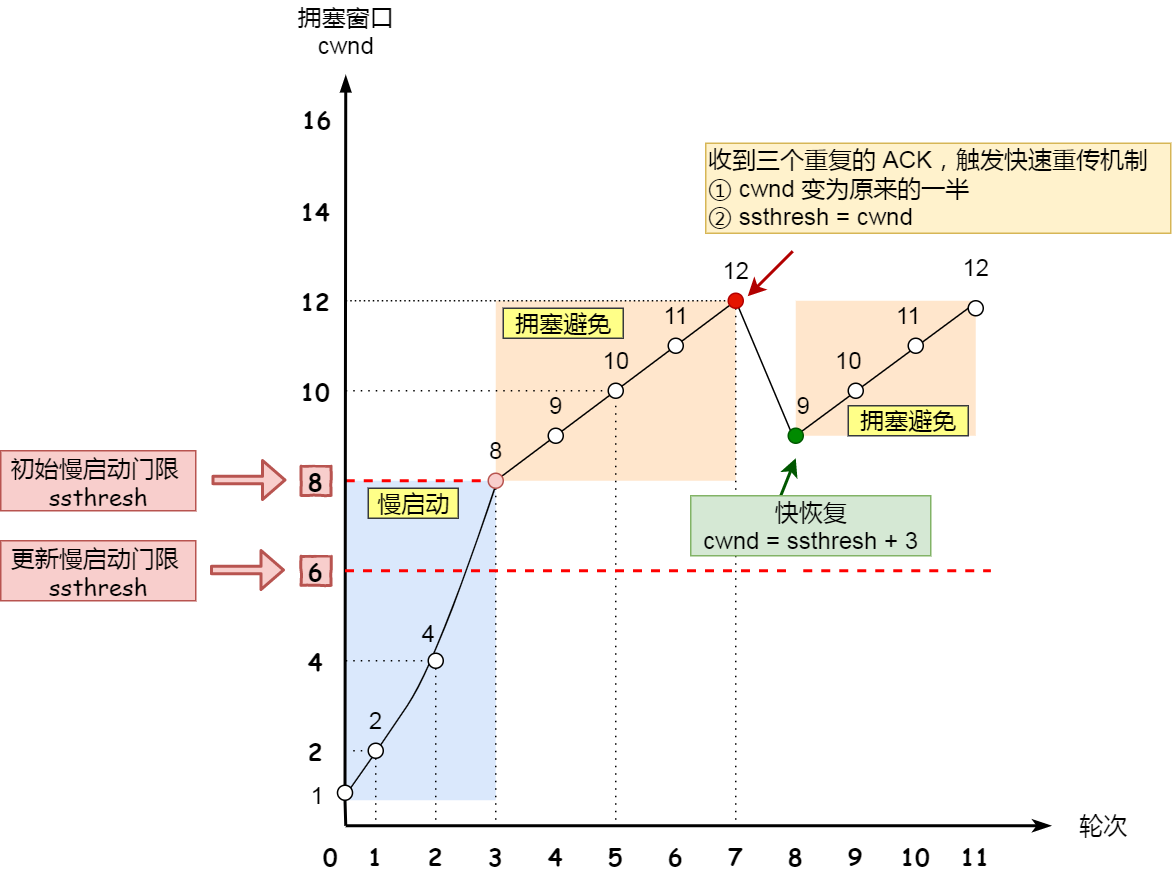
- 快速恢复。
- 当发生重传超时:
- 将ssthresh设置为当前cwnd的一半,
- 将cwnd重置为1个MSS。重新进入慢启动阶段。
- 当发生丢包:
- 将ssthresh设置为当前cwnd的一半。
- 将cwnd设置为新的ssthresh加上3个MSS,进入快速恢复阶段。
- 每收到一个重复ACK(和前三个重复ACK相同的ACK),cwnd增加1个MSS,直到收到一个对新数据的ACK。
- 退出快速恢复,进入拥塞避免状态。
- 当发生重传超时:
每收到一个重复ACK,cwnd增加1个MSS:表示网络中又有一个数据包离开了,可以再发送一个数据。当收到一个新数据的ACK时,意味着先前丢失的报文段已经被成功确认,快速恢复阶段正式结束。
算法缺陷:
- Reno只为单次丢包设计,在面对一个RTT内发生多个丢包时表现不佳。
- 假设发送方发出了10个数据包:1-10。
- 接收方收到了1、2、3、4、6、7、9、10。
- 当收到6,7,9时,会发送3个重复的请求序号5的ACK。
- 发送方立即重传5,并触发快速恢复,但是并不知道8也丢失了。
- 接收方收到5后,发送一个请求序号8的ACK。
- 发送方收到这个请求序号8的ACK后,退出快速恢复阶段,重新进入拥塞避免。
- 由于8已经发生丢包,最终会导致重传超时,cwnd直接降到1,重新进入慢启动阶段。
- 可能会将乱序到达的数据包误认为是丢包,导致错误地触发拥塞控制,降低传输速率。
- AIMD机制(减少快,增长慢)导致在大窗口场景下,一个数据报的丢失所带来的窗口缩小要花费很长的时间才能恢复。
TCP NewReno
NewReno解决了Reno在一个RTT内发生多个丢包时效率低下的问题。使得在快速恢复期间可以处理多个丢包,而无需等待超时。
- Reno快速恢复算法中当发送方收到一个新的ACK就退出快速恢复状态。
- New Reno算法中只有当快速恢复期间所有已经发送但尚未被确认的报文都被应答后才退出快速恢复状态。
这里引入两个概念:
- 部分应答(Partial ACK/PACK):如果收到的新ACK不是对已发送的最大序列号的确认,就称为PACK。PACK确认了在它之前丢失的包,但不确认后面那些在进入快速恢复之前发送的所有数据包。
- 恢复应答(Recovery ACK/RACK):如果收到的新ACK正好是已发送的最大序列号的确认,就称为RACK。发送方认为所有丢失的包都已被确认,拥塞结束,然后退出快速恢复状态。
NewReno算法改进了Reno算法中的快速恢复阶段:
- 当发生丢包:
- 将ssthresh设置为当前cwnd的一半。
- 将cwnd设置为新的ssthresh加上3个MSS,进入快速恢复阶段。
- 每收到一个重复ACK,cwnd增加1个MSS。
- 当收到新的ACK,如果是PACK,会并立即重传序号为ACK的数据包,而不需要等待超时。
- 直到收到的新的ACK为RACK,退出快速恢复,进入拥塞避免阶段。
NewReno举例:
- 假设发送方发出了10个数据包:1-10。
- 接收方收到了1、2、3、4、6、7、9、10。
- 当收到6,7,9时,会发送3个重复的请求序号5的ACK。
- 发送方立即重传5,并触发快速恢复,但是并不知道8也丢失了。
- 接收方收到5后,发送一个请求序号8的ACK。
- 发送方收到这个请求序号8的ACK后,不会退出快速恢复阶段。
- NewReno认为序号8的数据已丢失,它会立即重传数据包8。并持续停留在快速恢复状态。
- 直到收到请求序号11的ACK,NewReno知道所有在进入快速恢复之前发送的数据都已得到确认。
- 退出快速恢复,进入拥塞避免阶段。
NewReno算法缺陷:
- 依然依赖于重复 ACK。
- 依然存在对乱序数据包的误判。
TCP BIC
Tahoe/Reno/NewReno没有解决的问题:当网络带宽很高,但RTT很大时,拥塞窗口需要很长时间才能增长到足以利用全部带宽。
BIC的核心思想:在发现丢包后,通过二分查找的方式快速找到一个合适的cwnd。
- 慢启动:同Reno。
- 拥塞避免:类似Reno的线性增长,但比Reno的增长速度更快。
- 二分查找增长。
- 当发生丢包或重传超时后,将当前发生丢包时的拥塞窗口大小cwnd记录为$W_{max}$。
- 发生重传超时时,将cwnd直接重置为1个MSS,并将ssthresh更新为$W_{max}$/2 重新进入慢启动阶段。
- 发生丢包时,通过乘性减小将cwnd降低为$W_{min}$ = $W_{max}$/2。
- cwnd首先从$W_{min}$开始,每经过一个RTT,进行一次二分查找。
- 二分查找:将cwnd设置为Target = $W_{min}$ + ($W_{max}$ - $W_{min}$) / 2。
- 如果cwnd增长到Target的过程中没有发生丢包,说明网络容量可能更大:将$W_{min}$设置为新的cwnd,将Target设置为 $W_{min}$ + ($W_{max}$ - $W_{min}$) / 2。一直重复此步骤。
- 如果cwnd增长到Target的过程中发生了丢包,说明Target超过了网络容量:此时会将当前丢包时的拥塞窗口大小cwnd更新为$W_{max}$,重新进入新一轮的二分查找。
- 加性增长。
- 二分查找增长多轮后,$W_{min}$和$W_{max}$之间的差距会非常小,此时二分查找的步长会很小,为了避免过于保守,当cwnd非常接近$W_{max}$时,算法会切换到加性增长模式。
- 第一阶段,cwnd小于等于$W_{max}$:cwnd在每个RTT内增加一个固定的最大增量Smax,这使得cwnd能够缓慢而稳定地探测是否有可能超过最开始的$W_{max}$。
- 第二阶段,cwnd大于$W_{max}$,当cwnd的增长超过了之前的$W_{max}$后,如果没有发生丢包,这表明网络带宽已经增加。cwnd会以一个大于Smax的速率继续线性增长,以快速探测到新的网络容量。
BIC算法缺陷:
- 窗口振荡:激进增长->乘性减小->再次激进增长,这种振荡会降低网络的整体吞吐量。
- 不公平:在高带宽网络中能够迅速增加拥塞窗口,激进的增长模式会使它很快占据绝大多数带宽。
TCP CUBIC
CUBIC 的核心思想:使用一个三次函数来更加平滑地探测网络的可用带宽,从而解决BIC算法中存在的窗口振荡和不公平性问题。
CUBIC 的拥塞窗口增长曲线是一个以丢包点为基准的三次函数。
\[W(t) = C(t − K)^3 + W_{max}\]- $W(t)$ 是时间t时的拥塞窗口大小。
- $C$是一个可调参数,用于控制曲线的陡峭程度。
- $W_{max}$ 是上一次发生丢包时的拥塞窗口大小。
- K是一个时间常数,表示从当前cwnd增长到 $W_{max}$所需的时间。
这个三次函数曲线有以下关键特性:
- 凹形增长:当拥塞窗口离$W_{max}$较远时,曲线增长缓慢。这使得 CUBIC 能够长时间稳定地传输数据,而不会像 BIC 那样快速冲顶。
- 平坦区:当拥塞窗口接近上一次的$W_{max}$ 时,曲线变得非常平坦,几乎不增长。这为 CUBIC 提供了一个稳定的传输窗口,避免了 BIC 的窗口振荡问题。
- 凸形增长:当拥塞窗口在平坦区停留一段时间后,如果还没有发生丢包,CUBIC会认为网络容量可能已经增加,此时曲线的斜率变大,窗口开始加速增长,以快速探测新的带宽。
算法步骤:
- 慢启动:同Reno。
- 拥塞避免:当 cwnd 超过 ssthresh 后,CUBIC 进入拥塞避免阶段。在每个RTT,CUBIC 会计算一个新的 cwnd。它会同时计算三次函数增长和线性增长两种模式下的 cwnd,然后取其中较大的一个。
- 三次函数增长:根据前面提到的公式 W(t)计算。
- 线性增长:为了保证在网络带宽较低、RTT较短时也能有足够的增长,CUBIC依然会保持一个最小的线性增长,类似Reno的每个RTT增加1MSS。
- 拥塞恢复
- 记录丢包点:将当前的 cwnd 记录为新的 $W_{max}$。
- 乘性减小:将cwnd减小到 $W_{max}$的 80% (即 cwnd=$W_{max}$∗0.8)。
- 更新常数K:计算新的时间常数K,以便下一次的三次函数增长可以从新的cwnd处开始。K=($W_{max}$ * 0.2 / C)^(1/3) 然后,CUBIC回到拥塞避免阶段,并开始新的三次函数增长周期。